Introduction
After recently reviewing a suite of VET training and assessment materials purchased from a well-known commercial supplier, I published an article titled, ‘Human versus AI: The future of assessment design’.
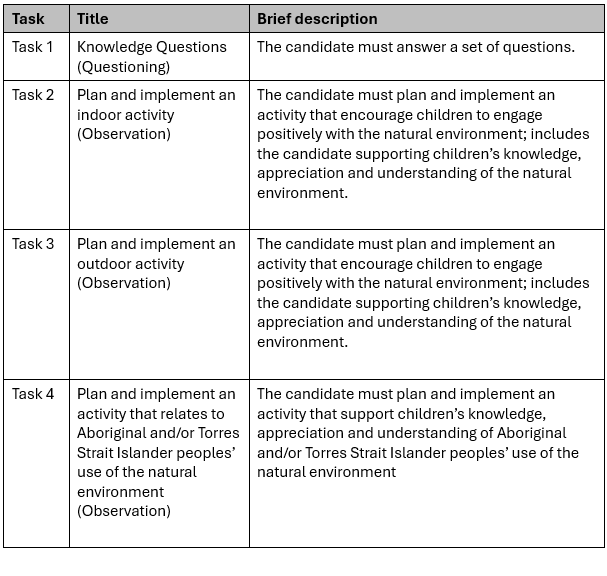
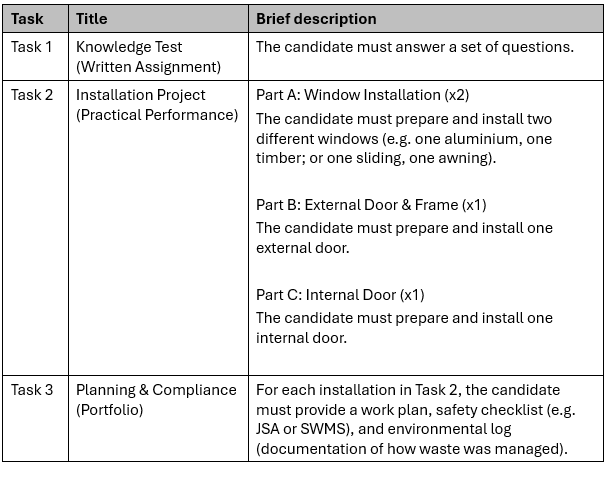
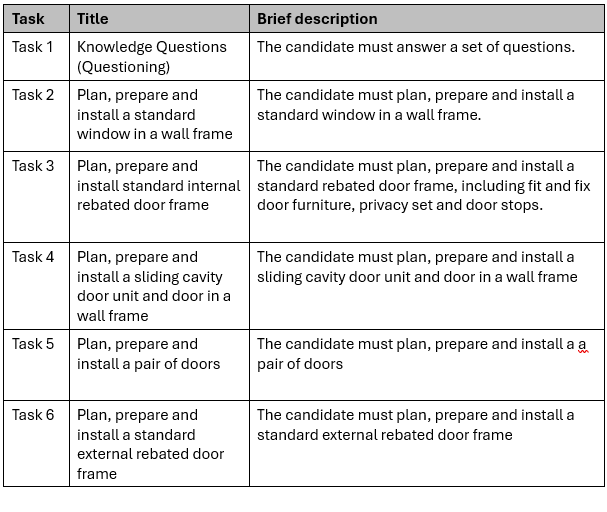
The resources I had reviewed were disappointingly unfit for purpose. I identified several critical issues, including:
- Overly complex numbering and an excessive amount of fragmented documents made navigation difficult.
- The content was cluttered with unnecessary instructions and jargon that is neither learner-friendly nor used in actual workplaces.
- The training and assessment materials lacked details and felt like generic templates had been used rather than materials tailored for the Unit of Competency.
The overall quality was bland and disconnected. This is highly characteristic of AI generated content. I later confirmed that this supplier is a ‘leading’ user of AI agents to produce their materials.
This is a following-on article warning all who use, or are considering to use, an AI agent to develop training and assessment materials. Also, it is a warning to RTOs who are intending to purchase training and assessment materials that have been produced by an AI agent.
I am not against using AI. I design and develop training and assessment materials, and I use an AI chatbot to assist me.
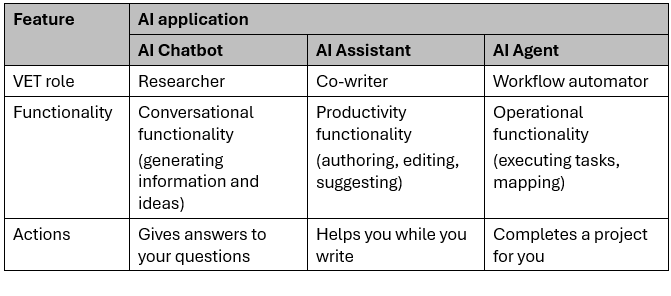
Let’s first look at the difference between an AI chatbot, AI assistant, and AI agent.
What is the difference between an AI chatbot, AI assistant, and AI agent?
An AI chatbot describes the ‘chat’ format or interface with AI. An AI assistant describes the overall role of helping the user. And an AI agent describes an AI that can act autonomously.
In the Australian VET system, the distinction between these three tools is defined by their autonomy and integration into an RTO compliance workflow.
Here is one specific example of how an instructional designer might use each of the three AI applications.
AI chatbot: The conversational researcher
When unpacking a new unit of competency, a chatbot acts as a reactive sounding board. You manually copy technical jargon or Performance Criteria into a separate window to request plain-English explanations or workplace scenarios. It requires a constant back-and-forth exchange, where the AI only knows what you explicitly provide in the chat. This manual ‘copy-paste’ workflow makes it a useful external tool for brainstorming and simplifying complex training requirements.
AI assistant: The integrated co-writer
As you draft learner guides or assessment tools within your word processor, an AI assistant works alongside you in real-time. Because it is context-aware, it ‘sees’ your active document, allowing it to suggest knowledge checks or generate marking rubrics based on your specific text. You can refine your tone or create content without switching windows. This integrated approach streamlines the design process by providing immediate, relevant support inside your workspace.
AI agent: The autonomous worker
For complex tasks like gap analysis, an AI agent operates with high autonomy. Once you set a goal, such as auditing assessment documents against a unit’s requirements from training.gov.au, it proactively executes a multi-step workflow. The agent navigates sites, downloads requirements, and identifies evidence gaps across files without further prompting. Unlike reactive tools, it completes the entire project independently and delivers a finished mapping matrix directly to your inbox.
The following is a summary comparing the above three AI applications.
Using AI agents to develop training and assessment materials
While AI agents offer significant efficiency in automating high-volume tasks, their use within the Australian VET sector, specifically under the 2025 Standards for RTOs, poses significant risks when developing training and assessment materials.
Here are five ways that relying on an AI agent can degrade the quality of training and assessment materials
The compliance illusion
AI agents excel at keyword matching but lack the expert judgment to determine if a task measures competency. An agent might incorrectly flag an assessment tool as ‘fully mapped’ just because it identifies specific terms from a Performance Criteria. However, it cannot determine if the task actually represents a valid or authentic measure of competency in a real-world workplace. This creates a ‘compliance illusion’ that can lead to non-compliance during a compliance audit.
Compromised intellectual property
Developing high-quality, training and assessment materials requires significant investment. Unless you are using a private AI system, uploading an RTO’s documents can mean your IP is used to train external AI models. For many RTOs, this is not just a quality issue but a major breach of data sovereignty and a loss of competitive advantage.
Pedagogically flawed
Training Packages on training.gov.au are complex and frequently updated. An AI agent may inadvertently pull historic definitions or draw from outdated datasets. Furthermore, it often lacks the ability to interpret the Companion Volume Implementation Guide, which provides the essential context for how a unit should actually be delivered and assessed, leading to mapping that may be technically correct but pedagogically flawed.
Lack of accountability for ‘hallucinated’ mapping
If an AI agent produces a mapping matrix that claims a specific content or assessment item covers a Performance Criteria or Foundation Skill when it actually doesn’t, the responsibility still rests entirely with the RTO. Unlike a human instructional designer who can provide an evidence-based rationale, an agent cannot justify its professional judgment. This lack of accountability results in unreliable mapping.
Erosion of contextualisation
A core requirement of the VET sector is contextualisation. This means tailoring training and assessments to a specific industry or learner cohort. AI agents tend to produce generic, one-size-fits-all training and assessment materials. Relying on an autonomous agent risks producing ‘cookie-cutter’ materials that fail to meet compliance or contextualised requirements.
Conclusion: Efficiency must not replace expertise
The allure of ‘set and forget’ AI agents for resource generation and compliance mapping is tempting for the time-poor VET sector. However, there is a vast chasm between functional automation and quality materials. Speed is irrelevant if the output fails a compliance audit.
Outsourcing instructional design to autonomous AI agents risks sacrificing human professional judgment. While AI can complete complex tasks at lightning speed, it lacks the capacity to understand workplace nuances, specific learner cohorts, or the pedagogical depth of a Training Package.
For RTOs, the warning is clear. Investigate how developers of training and assessment materials have used AI. Is it a chatbot for research, an assistant for drafting, or an agent for autonomous creation? As human oversight decreases, the risks to compliance and learner outcomes increase.
Technology should be embraced as a tool, not a replacement. Use chatbots to brainstorm or assistants to refine prose, but keep the human instructional designer at the centre of the development process. In an era of AI agents, human expertise is the only safeguard against a ‘cookie-cutter’ future.
Please tell me what you think!