Introduction
Recently, I reviewed a suite of VET training and assessment materials purchased from a well-known commercial supplier. Despite the provider’s reputation, the resources were disappointingly unfit for purpose. Focusing specifically on the assessment components, I identified several critical issues:
- Poor usability: Overly complex numbering and an excessive amount of fragmented documents made navigation difficult.
- Language and literacy barriers: The content was cluttered with unnecessary instructions and jargon that is neither learner-friendly nor used in actual workplaces.
- Lack of context: Assessments lacked specific scenario details and felt like generic templates rather than materials tailored to the unit of competency being assessed.
The overall quality was bland and disconnected. This is highly characteristic of AI generated content. I later confirmed that this supplier is indeed a ‘leading’ user of AI to produce their materials. This serves as a stark reminder: while AI is a powerful tool, it cannot replace the human expertise required to create meaningful, compliant VET resources.
Structuring assessment tasks
While there are typically multiple ways to structure assessment tasks, the quality of that design varies significantly. At the highest level, a structure is effective, efficient, and compliant, balancing regulatory requirements with a smooth user experience. Other designs may be adequate and compliant but ultimately burdensome, creating unnecessary hurdles for both the learner and the assessor. More concerning are structures that are inadequate but appear compliant on the surface, masking deeper flaws. Finally, some structures are simply inadequate and obviously non-compliant, failing to meet the basic standards required for a valid assessment.
To illustrate these differences in practice, I have provided the following three distinct comparisons between AI-generated and human-designed assessment tasks across various industry sectors. These three examples highlight how a human-led strategy ensures that the structure remains both pedagogical and practical. While the AI versions may tick boxes in a literal sense, the human-designed versions demonstrate a deeper understanding of how to weave complex requirements into a logical, streamlined workflow that supports an effective, efficient and compliant assessment process.
Example 1. BSBCMM411 Make presentations
The following is the Performance Evidence for the BSBCMM411 Make presentations unit of competency.

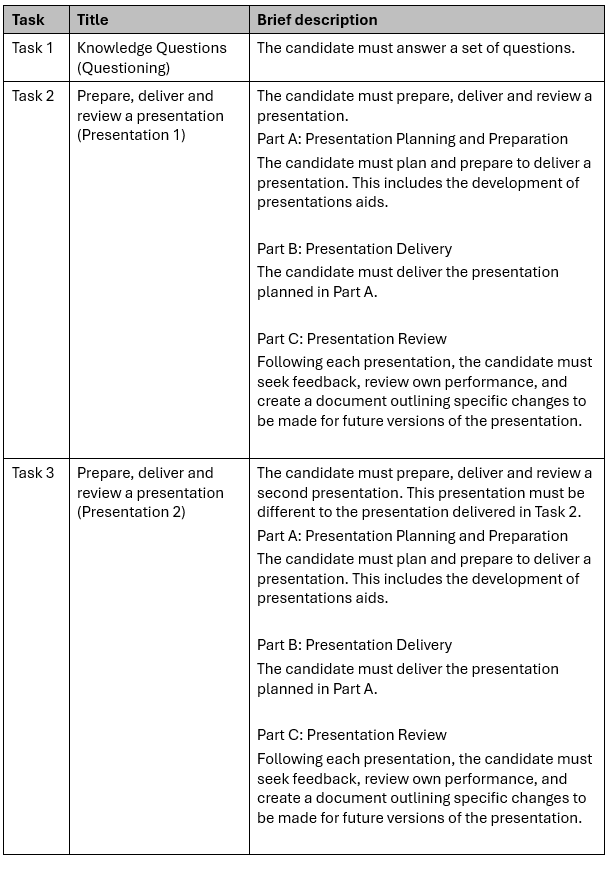
The following are assessment tasks generated by AI.1
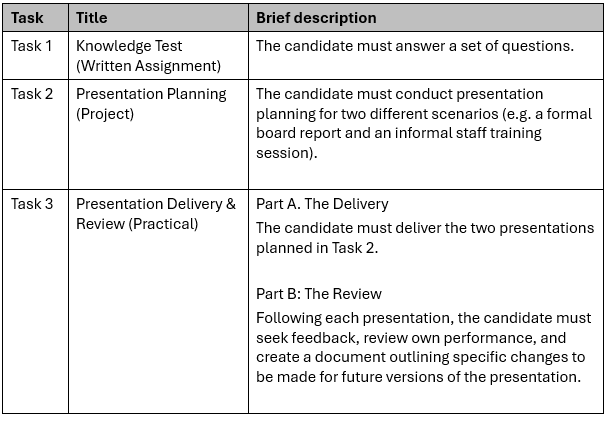
The following show the assessment tasks generated by a human.2
The following is a list1 of five reasons why the human-generated assessment structure for BSBCMM411 unit is superior to the AI-generated version.
- Logical chunking of workflow: The human version groups the planning, delivery, and review into a single cohesive task for each presentation (Task 2 and Task 3), whereas the AI splits the planning and delivery into entirely separate tasks.
- Reinforcement of the full cycle: By requiring the candidate to complete the entire cycle (Plan-Deliver-Review) for the first presentation before moving to the second, the human structure allows for immediate application of “lessons learned”.
- Explicit material development: The human-generated structure explicitly includes the “development of presentation aids” within the planning phase, ensuring this critical requirement is not overlooked, while the AI description is more generic.
- Clarity on “different” scenarios: The human structure clearly mandates that Task 3 must be a second presentation that is “different to the presentation delivered in Task 2”, providing a clear instruction for meeting the unit’s diversity requirements.
- Reduced administrative confusion: In the AI structure, an assessor must jump back and forth between Task 2 (Planning) and Task 3 (Delivery) to grade one presentation. The human structure allows an assessor to finalise all evidence for “Presentation 1” within a single task block.
Example 2. CHCECE037 Support children to connect with the natural environment
The following is the Performance Evidence for the CHCECE037 Support children to connect with the natural environment unit of competency.

The following are assessment tasks generated by AI.1
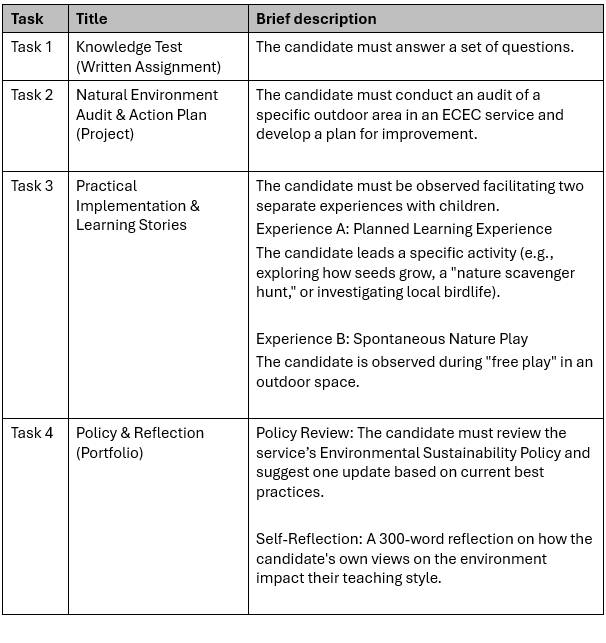
The following show the assessment tasks generated by a human.2
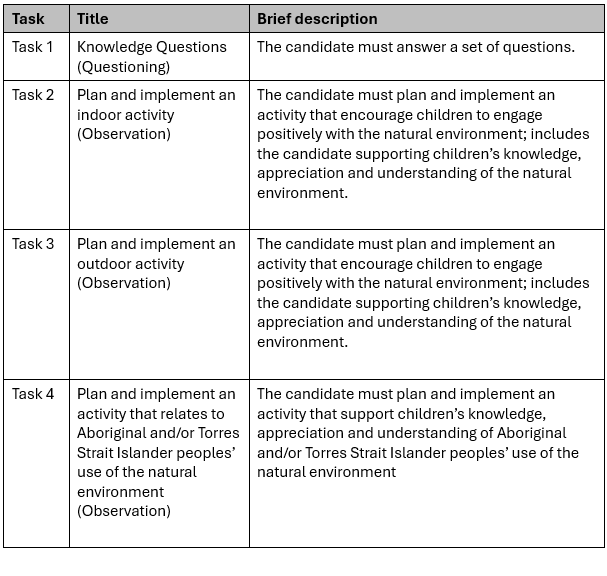
The following is a list1 of three reasons why the human-generated assessment structure for CHCECE037 unit is superior to the AI-generated version.
1. Direct alignment with assessment requirements
The Performance Evidence explicitly requires evidence of supporting children’s knowledge on three occasions.
- Human Design: Tasks 2, 3, and 4 in the human version clearly provide these three distinct opportunities (Indoor, Outdoor, and Aboriginal/Torres Strait Islander focused).
- AI Design: The AI version only lists two clear implementation experiences (Experience A and B) in Task 3, potentially failing to meet the “three occasions” mandate.
2. Specific inclusion of cultural perspectives
The unit requires that at least one occasion must involve Aboriginal and/or Torres Strait Islander peoples’ use of the natural environment.
- Human Design: Dedicates a specific, standalone task (Task 4) to ensure this mandatory requirement is met and observed.
- AI Design: Completely omits this specific cultural requirement in its brief descriptions, focusing instead on generic activities like “seed growing” or “scavenger hunts”.
3. Clear Indoor/Outdoor distinction
The unit requires one indoor and one outdoor opportunity.
- Human Design: Explicitly structures Task 2 as an indoor activity and Task 3 as an outdoor activity, ensuring the candidate covers both environments.
- AI Design: Focuses heavily on the outdoor environment (Task 2 audit and Task 3 “nature play”), without clearly designating or requiring a specific indoor engagement.
Example 3. CPCCCA3010 Install windows and doors
The following is the Performance Evidence for the CPCCCA3010 Install windows and doors unit of competency.

The following are assessment tasks generated by AI.1
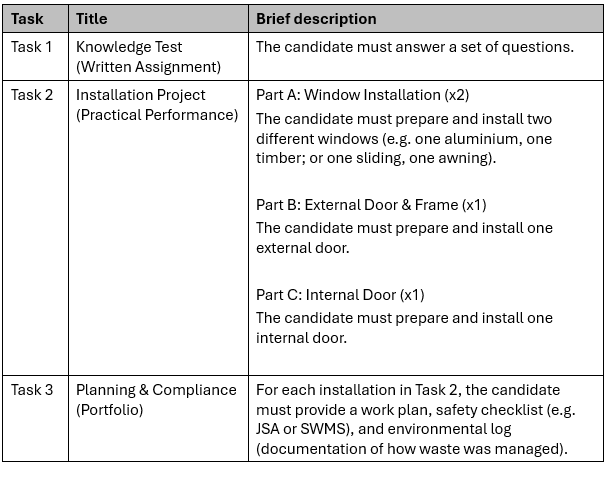
The following show the assessment tasks generated by a human.2
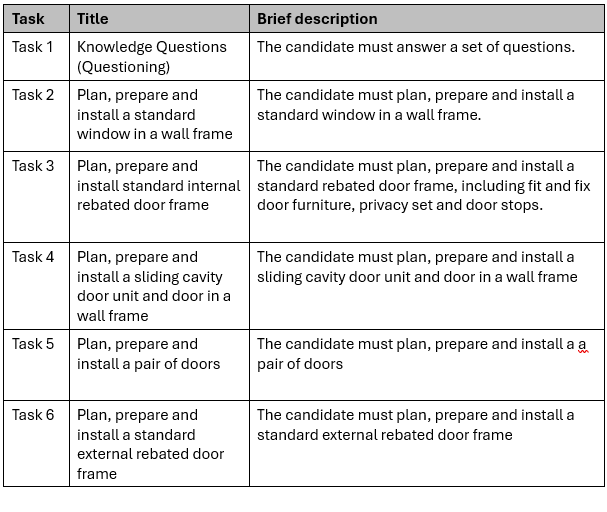
The human-generated assessment tasks ensure full compliance with the specific Performance Evidence for CPCCCA3010 unit. The following is a list1 of three reasons why the human-generated assessment structure is superior to the AI-generated version.
1. Inclusion of specific door types
The Performance Evidence requires the installation of a sliding cavity door unit and door and a pair of doors.
- Human Design: Includes “Task 4” specifically for the sliding cavity door and “Task 5” for the pair of doors.
- AI Design: Uses generic categories like “External Door” and “Internal Door”, which fails to explicitly require these two specialised installation types.
2. Accurate quantity of installations
- Human Design: The human-generated tasks align perfectly with the requirement to install “a” (single) standard window
- AI Design: The AI-generated Task 2 requires the candidate to install two windows, which adds an unnecessary burden not specified in the performance evidence.
3. Integration of planning and installation
- Human Design: Integrates the “plan” and “prepare” requirements directly into every individual practical task (Tasks 2, 3, 4, 5, and 6). This ensures that the planning is context-specific to the unique requirements of a window, a sliding cavity door, or a pair of doors.
- AI Design: Separates “Planning & Compliance” into a standalone Portfolio (Task 3). By treating planning as a generic administrative exercise rather than an embedded part of the installation process, the AI version risks a disconnect between the candidate’s theoretical plan and the actual technical preparation required for different types of frames and doors.
Conclusion: Why the human designer is irreplaceable
The examples above highlight a consistent pattern: while AI can generate a list of tasks that look like an assessment, it lacks the professional judgment to design a strategy that is actually fit for purpose.
The disparity between these two approaches boils down to three critical factors:
- Nuance and compliance: As seen in the CPCCCA3010 and CHCECE037 examples, AI frequently misses specific requirements that are essential for a finding of competency. A human designer reads between the lines of a Training Package to ensure no mandatory evidence is overlooked.
- Pedagogical workflow: AI tends to “atomise” tasks into clinical, disconnected steps. In contrast, human designers understand how a job actually functions. By grouping planning, execution, and review into a single cohesive task, as seen in the BSBCMM411 example, humans create a natural assessment flow that mirrors real-world workplace practice rather than a fragmented digital checklist.
- The “Goldilocks” principle of evidence: AI often oscillates between two extremes: providing too little detail or creating “assessment bloat” by requiring more work than is necessary. A human expert knows how to design a strategy that is “just right”, meeting every requirement specified by the unit of competency without placing an unnecessary administrative burden on the learner or the assessor.
AI is a powerful assistant for brainstorming or drafting, but it is a poor architect. In the high-stakes environment of VET compliance, an assessment strategy is more than just a document. It is a roadmap that needs to be accurate and compliant. The “human-in-the-loop” must remain the “human-at-the-helm.”
Investing in human-led design isn’t just about avoiding “bland” materials; it’s about ensuring that our VET students are truly competent and that our RTOs remain compliant.
Footnotes:
1 On the 2nd of March 2026, Gemini was the AI platform used to generate the assessment tasks for the three examples. It was also used to compare the assessment structure generated by AI and the human.
2 Alan Maguire was the human who generated the assessment tasks for the three examples. He has had more than 40 years experience designing training and assessment. Alan may be getting older, but he is not yet redundant.
